Resumen
En este trabajo se realiza una descripción y comparativa de dos normas de compresión de vídeo VP8 y H264. Tras una introducción al trabajo, se detallarán las descripciones técnicas de ambos estándares para posteriormente, proceder a la evaluación técnica de prestaciones y comparación de ambos estándares a través de gráficos y ejemplos. Para finalizar se expondrán las conclusiones obtenidas.
Este trabajo se enmarca dentro del objetivo de fomentar el aprendizaje autónomo de los alumnos, y con él se persigue acercar al lector una idea suficientemente detallada y fundamentada de los estándares de compresión de vdeo VP8 y H264.
Actualmente el incremento de la demanda de contenidos audiovisuales distribuidos a través de distintas redes y plataformas y a su vez la mejora de las prestaciones, tanto de las mismas redes como del equipo utilizado para la codificación, decodificación y reproducción de contenidos ha provocado una necesaria renovación de la forma en que dichos contenidos se comprimen y codifican.
En este contexto se crean las normas VP8 y H264 con el objetivo de ofrecer contenidos de alta calidad que además puedan ser visualizados en todo tipo de dispositivos e incorporen facilidades para garantizar la Calidad del Servicio (QoS), sin embargo cabe preguntarse, ¿cuál de ellas es mejor y en qué situaciones? Esa pregunta intentaremos responderla a lo largo de este trabajo.
2. DESCRIPCIÓN TÉCNICA DE H264
2.1. Introducción
El estándar de codificación de vídeo H.264 fue implementado en conjunto por dos organismos, el ITU-T Video Coding Experts Group (VCEG) y el ISO/IEC Moving Picture Experts Group (MPEG). A pesar de haber sido implementado en conjunto y que el estándar es exactamente el mismo, los organismos difieren en cuanto al nombre, el ITU lo numera como un nuevo estándar H.264 y en MPEG lo numeran como MPEG-4 parte 10 (AVC).
El objetivo de este estándar es conseguir incrementar la calidad aumentando también la eficiencia en la codificación. Para ello se buscaba entre otras cosas, intentar reducir en hasta un 50% el bit-rate o caudal generado respecto a estándares anteriores. Además de esto, el estándar mejorar su flexibilidad en diversos términos para lograr la ganancia de compresión y reducir el coste computacional. Por último, el estándar debía conseguir una buena resistencia frente a errores en determinados ambientes, en los cuales puede haber una elevada tasa de errores (redes inalámbricas o comunicaciones móviles).
2.2. Estructura de h.264
La estructura de H264 es similar a la de sus antecesores. Mantiene un algoritmo de predicción y transformación, mantiene el control del bit-rate o caudal, la predicción por compensación de movimiento para reducir la redundancia temporal sigue funcionando de la misma forma y sigue utilizando un codificador de entropía.
Para conseguir mejoras respecto a los estándares anteriores, el diseño de H.264 / AVC consta de dos capas bastante diferenciadas:
- Video Coding Layer (VCL): Esta capa es la que se encarga de los contenidos de vídeo y las tareas que se realizan normalmente en la fase de codificación.
- Network Abstraction Layer (NAL): Esta capa se encarga de abstraerse de los datos y consigue que el bit-stream o flujo de bits de salida del codificador sea compatible con todos los posibles canales de transmisión o medios de almacenamiento.
2.3. Capa de VCL
Esta capa es básicamente la que se encarga de la parte de codificación del vídeo. Para ello los datos codificados del vídeo se estructuran de forma que dada una secuencia de vídeo a codificar, ésta se divide en frames, a su vez los frames se dividen en slices y cada slice se divide en macrobloques (MB), los cuales se dividen a su vez en bloques.
Al igual que en sus antecesores, en H.264 distinguimos tres tipos de frames, frames I para aquellos que su información no depende de otros frames para decodificarse, frames P que se codifican en base a la información de los frames I o P previos más cercanos, y por último frames B que utilizan predicción bidireccional (pasada y futura), utilizando también los frames I o P más cercanos.
Un slice es una secuencia de MBs que pueden tener distintos tamaños (tamaños flexibles). En el caso de grupos de slices, la posición de un MB se determina por medio de un mapa que representa al grupo de slices. El mapa indica a qué grupo de slices pertenece el MB en cuestión.
Esta sería la estructura de la capa VLC del estándar H.264.

Figura 1. Diagrama de flujo de un codificador H.264
La mejora de este estándar respecto a los anteriores es la forma en la que opera cada uno de estos bloques funcionales indicados en el esquema. Ahora describiremos brevemente el funcionamiento del proceso de codificación del vídeo mediante este estándar.
2.4. Proceso de codificación del video
En la figura 1 podemos observar que el algoritmo en primer lugar elige entre codificación INTRA-frame o INTER-frame.
La codificación INTRA se utiliza para eliminar la redundancia espacial de un frame, mientras que la codificación INTER es más eficiente, reduce la redundancia temporal y se implementa utilizando frames de tipo P o B. En la codificación INTER también se emplean los vectores de movimiento que consiguen reducir aún más la redundancia temporal entre los frames. Antes de realizar la predicción de los movimientos se realiza un filtrado de los bloques para reducir los posibles errores o distorsión que se haya introducido en un bloque debido al proceso de la cuantificación.
Antes del proceso de cuantificación, la imagen residual se comprime más utilizando una transformada (dependiendo del tipo de residuo, Hadamard o Transformada Entera). Por último, los vectores de movimiento y los coeficientes ya cuantificados se codifican utilizando un codificador de entropía adaptativo como el CAVLC (Context–Adaptive Variable Length Codes) o el CABAC (Context–Adaptive Binary Arithmetic Codes).
2.5. Mejoras en h.264
Tras el resumen del proceso, observamos algunas novedades, respecto a anteriores estándares, las cuales detallaremos a continuación:
- Predicción Intra-frame.
- Cuando un bloque o MB es codificado como Intra se realiza una predicción basada en bloques o MB codificados anteriormente en esa imagen.Al bloque o MB que se codifica se le resta la predicción que se le ha realizado. Sólo pueden utilizar muestras que pertenezcan al mismo slice. De esta forma habrá propagación espacial si se encuentran errores, aunque no demasiado grave.
- El bloque de luminancia bajo predicción, puede formarse por todo el bloque de 16x16 muestras o por sub-bloques de 4x4 muestras.
- Existen cuatro modos de predicción para bloques de luminancia de 16x16 muestras.
- Para cada bloque de luminancia de 4x4, se selecciona un modo de predicción de entre nueve modos posibles.

Figura 2 - Tipos de predicción Intra-Frame para tamaños 4x4
- Estimación y Compensación de movimiento con diferentes tamaños de macrobloque.
- Un macrobloque de luminancia de 16x16 muestras, puede dividirse en pequeños bloques de hasta 4x4.
- Existen cuatro casos: 16x16, 16,8, 8x16 y 8x8 para los macrobloques de 16x16.
- También existen cuatro casos para un macrobloque de luminancia de 8x8: 8x8, 8x4, 4x8, 4x4.

Figura 3 - Particiones de macrobloques y sub-macrobloques
- Cuanto más pequeño sea el bloque que queremos predecir, mayor será el número de bits para representar los vectores de movimiento, pero al utilizar particiones pequeñas se puede reducir considerablemente el residuo tras realizar la compensación de movimiento.
- La selección del tamaño de la partición depende de las características del video de entrada. En general, una partición grande es beneficiosa cuando las muestras del bloque son homogéneas y una partición pequeña cuando el nivel de detalle es mayor.
- Vectores de movimiento con precisión de 1/4 ó 1/8 de pixel.
- En el proceso de codificación INTER, se pueden procesar bloques de hasta 4x4 muestras de luminancia, utilizando una precisión en los vectores de movimiento de hasta un cuarto o un octavo de muestra. La compensación de movimiento con fracciones consigue una mayor compresión y mejor calidad de la imagen que con la compensación de movimiento entera, aunque este proceso sea más costoso computacionalmente para el codificador.
- Más flexibilidad en el uso de Frames de tipo B y P.
- Con H.264 los frames de tipo B se pueden utilizar como referencia para la codificación INTER de otros frames y además pueden referenciar a 2 frames del pasado, 2 del futuro o uno del pasado y otro del futuro.

Figura 4 - Ejemplo de dependencias entre frames en H.264
- Los frames de tipo P también pueden hacer referencia a multiples frames con un máximo de hasta 16.
- Utilización de 3 tipos de transformadas dependiendo del residuo que vamos a codificar.
- Transformada Hadamard 4x4: Coeficientes DC de luminancia en MBs codificados como tipo Intra y tamaño 16x16.
- Transformada Hadamard 2x2: Coeficientes DC de crominancia de cualquier tipo.
- Transformada DCT Entera 4x4: El resto de bloques.
- Filtro de deblocking en el codificador.
- El filtro utilizado por H.264 mejora la calidad y reduce la distorsión en los frames debido a los efectos de la transformada DCT a nivel de bloque 4x4. Esta distorsión también se incrementa al utilizar diferentes tamaños de MB para realizar la estimación y compensación del movimiento.
- Estos filtros se pueden aplicar a nivel de codificador o decodificador.
- A nivel de codificador operan antes de realizar la estimación y compensación de movimiento. Estos filtros deben estar estandarizados.
- A nivel de decodificador realizan las operaciones del filtro antes de mostrar el frame en pantalla. Estos filtros no necesitan estar estandarizados y cada fabricante de decodificadores tiene libertad para implementarlos.

Figura 5 - Comparativa al aplicar el filtro de deblocking - [Apuntes]
- Modos de codificación de entropía adicionales (CAVLC y CABAC).
- La codificación de entropía se basa en tablas previamente definidas, las cuales contienen códigos de longitud variable y que están basadas en distribuciones de probabilidad de datos obtenidos en determinadas secuencias de video genérico.
- H.264 utiliza diferentes códigos de longitud variable.
- UVLC (Universal VLCs). Este método es similar en los anteriores estándares.
- CAVLC (Context Adaptive VLCs). Coeficientes escaneados desde el final hasta el principio y no utiliza EOB (fin de bloque). El número de coeficientes también es codificado.
- CABAC (Context-based Adaptive Binary Arithmetic Codes). Utiliza modelos de probabilidad dinámicos que se adaptan a los símbolos que queremos codificar. Nos permite alcanzar entre un 5 y un 15% menos de bit-rate o caudal.
- Para leer los datos a codificar se pueden utilizar 2 tipos de búsqueda: una en zigzag una alternada.
Todas estas mejoras anteriormente descritas, permiten codificar con una mayor calidad y más compresión que respecto a estándares anteriores, aunque todas estas mejoras conllevan un aumento en la complejidad de la implementación de codificadores y decodificadores, así como un mayor coste computacional por parte de éstos.
En H.264, al igual que en estándares anteriores, se definen diferentes tipos de perfiles y niveles, los cuales especifican restricciones en el flujo de bits.
2.6. Perfiles H.264
Respecto a los perfiles de H.264 cabe destacar que, en la primera versión del H.264 existen tres: baseline, main y extended.
· El perfil baseline se aplica a los servicios de conversación en tiempo real, como vídeo conferencia y vídeo teléfono.
· El perfil main es para aplicaciones de almacenamiento digital de vídeo y datos, así como de transmisión de televisión.
· El perfil extended es aplicable también a servicios de multimedia en Internet como, por ejemplo, el streaming.
La última versión del H.264, define cuatro perfiles de tipo high, definidos como extensiones para aplicaciones de distribución de determinados contenidos y para edición y post procesamiento: High, High 10, High 4:2:2 y High 4:4:4.
En la siguiente figura podemos apreciar la relación que existe entre los diferentes perfiles de H.264 / AVC y los elementos que se añaden o eliminan de unos perfiles a otros.

Figura 6 - Perfiles de H.264 - [Apuntes]
2.8. Capa de NAL
La capa NAL (Network Abstraction Layer) consta de algunos conceptos los cuales detallaremos a continuación:
· NAL Units.
o Una vez que el video ya está codificado mediante se organiza en paquetes.
Hay 2 tipos de paquetes:
§ VCL NAL units: Contienen la información del vídeo.
§ Non-VCL NAL units: Contienen información de control.
- Parameter Sets
- Es el conjunto de parámetros usados para la codificación y decodificación en esta capa (sequence parameter sets, picture parameter sets, etc.)
- Access Units
- Estas unidades están formadas por un conjunto de NAL units.
- Cada decodificación de un Access Unit corresponde a la decodificación de un determinado frame.
3. DESCRIPCIÓN TÉCNICA DE VP8
3.1. Breve historia de VP8.
Este códec es creado por On2 Technologies, una empresa especializada en desarrollar tecnologías de compresión de vídeo quienes ya habían creado otros códecs como VP3, VP4, VP5 (2002) VP6 (2003) y VP7.
Esta empresa ya era conocida por sus grandes logros como VP6 ya que se trata de un códec avanzado con calidades superiores a Windows Media Video, MPEG-4 y RealVideo por sus avanzadas técnicas para la recuperación de errores, la posibilidad de comprimir material de alta definición (HD) sin restricciones en el codificador o el soporte de codificación multi- paso entre otras. En general los códecs diseñados por On2 son capaces de competir con los códecs comerciales más importantes de la época.
Con el paso del tiempo, en 2009 Google adquiere On2 Tecnologies y posteriormente el 19 de mayo de 2010 libera el códec VP8, pasando este a ser de código abierto.
Junto al lanzamiento del código fuente de VP8 también se presentó el proyecto llamado "WebM" [WebM] que ofrece nuevas contribuciones al códec (y también incluye el códec de audio Vorbis) y apoyo a empresas como Opera o Mozilla, que deciden utilizar esta tecnología en sus desarrollos.
3.1. Introducción y formato general de VP8
Aunque VP8 parece ser un formato de vídeo muy novedoso, en verdad la idea general que usa para codificar y decodificar es muy parecida a todos los formatos de vídeo modernos, salvo algunos cambios en los pasos que se realizan.
VP8 se diseño para manejar el formato de imagen utilizado por la mayoría de los vídeos en la web: 4:2:0 con color de 8 bits por canal de profundidad, escaneo progresivo (no entrelazado) y dimensiones de imagen 16383x16383 pixeles.
Sus principales características son:
- Transformada híbrida con cuantificación adaptativa.
- Referencias flexibles a fotogramas.
- Predicción Intra e Inter eficiente.
- Alto rendimiento en interpolación de Sub-Pixeles.
- Filtro de bucle adaptativo.
- Codificación de entropía adaptativo a nivel de marco.
- Partición de dato con procesamiento en paralelo.
3.3. Marcos de referencia en VP8
VP8 usa tres tipos de marcos de referencia para predecir, estos son los siguientes: La última imagen (last frame), un marco de referencia alternativo (alternate reference frame), y los marcos de Oro (Golden reference frame). A continuación se detallarán estos dos últimos por ser bastante novedosos.
Golden Reference Frames
Tras la realización de una serie de estudios sobre los marcos de referencia, se decide diseñar un "buffer frame" de referencia para almacenar un fotograma de vídeo de un punto del pasado, esto se conoce como "marco de referencia de oro". Además, el formato define una serie de flags en el flujo de bits que notifica cómo y cuándo se actualiza este buffer. Con esto se mejora la eficiencia en la codificación y en la compresión de muchas escenas de vídeo.
AlternateReference Frame
Este tipo de referencias tienen como novedad, a diferencia de otros tipos de marcos de referencia usados en la compresión de vídeo, que pueden ser mostrados o no. Es decir, pueden ser únicamente utilizados como referencias para mejorar la predicción y no mostrarse.
3.4. Predicción usada en VP8.
Con respecto al tipo de predicción usado por VP8 se debe tener en cuenta que para codificar un fotograma de vídeo, si el códec en cuestión está basado en bloques como VP8, primero se tendrá que dividir en zonas más pequeñas llamadas macrobloques, así dentro de cada uno de estos se podrá predecir el movimiento redundante, es decir, aquel que es similar al movimiento actual. Con esto se consigue reducir considerablemente la cantidad de información a comprimir y por tanto realizar una compresión más eficaz.

Figura 7- Predicción en VP8 - [WebM]
Una vez en contexto, se determina que un codificador VP8 utiliza dos tipos de predicción, para fotogramas Intra (I-Frames) y para fotogramas Inter (P-Frames), de este modo se usarán los de tipo Intra para datos dentro de un vídeo y los de tipo Inter par aquellos marcos previamente codificados. Se ha de destacar que los datos de la señal residual que se crea al codificar, utilizan otras técnicas, tales como la codificación por transformada.
Dentro de cada tipo de predicción existen diferentes modos para predecir. Para entrar más en detalle se usará la configuración de macrobloque expresada en la siguiente imagen.

Figura 8 - Configuración del Macrobloque - [WebM]
Para a continuación detallar los diferentes modos usados para cada tipo de predicción: Modos de Predicción Intra (I-Frames):
Los modos de predicción Intra utilizan tres tipos de bloques para adivinar el contenido de estos sin hacer referencia a otros marcos, estos son:
- 4x4 Luminancias.
- 16x16 Luminancias.
- 8x8 Crominancias.
A su vez, para cada tipo de macrobloque se establecen distintos modos de predicción:
H_PRED (predicción horizontal): Se rellena cada columna de la cuadricula con una copia de la columna de la izquierda.

Figura 9 - Predicción horizontal - [WebM]
V_PRED (predicción vertical): Se rellena cada fila del bloque con una copia de la fila A.

Figura 10 - Predicción vertical - [WebM]
DC_PRED (Predicción DC): Se rellena el bloque con el valor promedio de los pixeles por encima de la fila A y de la columna de la izquierda L.

Figura 11 - Predicción DC - [WebM]
TM_PRED (Predicción TrueMotion): Esta técnica de compresión es única para VP8 en modos de predicción. Es desarrollada por On2 Tecnologies, y consiste en utilizar, además de la fila A y la columna L para predecir, el pixel P por encima y a la izquierda de cada bloque. Con lo que se realiza la diferencia entre los pixeles en A (a partir de P) y es propagada utilizando los pixeles de L para empezar cada fila.
Con todo esto y basándonos en la cuadrícula de la Figura 8, se puede determinar la ecuación usada por TM_PRED para representar cada valor X en el bloque actual, es la siguiente:
X ij = L i + j A - C (i, j = 0, 1, 2, 3)
Se ha de tener en cuenta que aunque en los ejemplos anteriores se usan bloques de 4x4, los modos de predicción funcionan exactamente igual para bloques de 8x8 y 16x16.
Modos de Predicción Inter (P-Frames):
En VP8, los modos de predicción Inter se utilizan para adivinar el contenido de un bloque haciendo referencia a los últimos marcos. En este aspecto existen dos componentes principales: Marcos de referencia (detallados en el punto 3.3 de este documento) y vectores de movimiento.
Por tanto, se entenderá como "Índice de Movimiento" al desplazamiento que se realiza dentro de este marco. Un bloque típico de predicción Inter, se construye con un vector de movimiento, donde se copiará un bloque desde una de las tres tramas de referencia.
VP8 codifica vectores de movimiento de forma muy eficiente mediante el uso de los vectores de movimiento de los macrobloques vecinos (cada macrobloque incluye un bloque
16x16 de luminancia y dos 8x8 de Crominancias). Por ejemplo, en los modos de predicción "Nearest" y "Near", se hace uso del último y el penúltimo vector de movimiento de macrobloques vecinos no-cero.
De forma adicional, VP8 posee un método de predicción Inter muy sofisticado y flexible llamado SPLITMV. Este modo fue diseñado para permitir la partición de un macrobloque en sub-bloques, y lograr así una mejor predicción. SPLITMV es muy útil cuando los objetos de una macrobloque tienen características diferentes de movimiento, y en consecuente cada sub- bloque puede tener su propio vector de movimiento y usar referencias a vectores de movimiento de sub-bloques vecinos. Por ejemplo: Un macrobloque de 16x16 de luminancias se didive en 16 bloques de 4x4:

Figura 12 - Ejemplo SPLITMV - [WebM]
Se puede observar que en el cuadro superior izquierdo "New", se codifica un nuevo vector de movimiento, con un nuevo bloque de 4x4, utilizando el vector de movimiento de la izquierda y arriba respectivamente. Con lo que se forman de forma efectiva las particiones del macrobloque de 16x16 en tres diferentes segmentos con tres vectores de movimiento distinto (representado por 1,2 y 3).

Figura 13 - Codificación bloque New en SPLITMV - [WebM]
3.5. Transformada y cuantificación
De forma similar a los códecs anteriores a VP8 y de la familia VPx, se utiliza la codificación por Transformada del residuo que se genera tras las predicciones intra e inter. VP8 divide los bloques de luminancia y crominancias en bloques de tamaño 4x4, para posteriormente aplicar la Transformada y el proceso de cuantificación.
Se aplica DCT (transformada discreta del coseno), a todos los bloques de tamaño 4x4 tanto de luminancia como de crominancias para convertir la señal de residuo en coeficientes transformados.
Para macrobloques de 16x16 con los modos de predicción de luminancia, se extraen cada uno de los coeficientes DC de cada uno de los 16 bloques de 4x4 y se forma un nuevo bloque 4x4 al que se le aplica WHT (Walsh-Hadamard transform). WHT es usado para reducir aún más la redundancia entre los coeficientes DC de los 16 bloques de 4x4 dentro de un macrobloque.
VP8 posee además de un proceso de cuantificación adaptativa diseñado para trabajar en una gama de calidad de ~30dB a ~45dB. Dentro de este rango se definen 128 niveles de cuantificación en su proceso de cuantificación escalar. Además para cada cuadro de vídeo VP8 permite usar diferentes niveles de cuantificación.
3.6. Codificación de entropía en VP8
Cuando se hace referencia a la codificación de entropía, se trata de tomar toda la información de todos los demás procesos: coeficientes DCT, modos de predicción, vectores de movimiento etc. Y comprimirlos sin perdidas en el archivo de salida final.
A excepción de algunos bits de cabecera que se codifican como valores brutos o sin comprimir, la mayoría de los datos se codifican usando un codificador aritmético booleano. Este codificador codifica un valor booleano (0/1) en cada ocasión y es usado para comprimir
sin pérdidas.
La mayoría de los valores de VP8 se digitalizan con una serie de valores booleanos de manera similar a como se crea un árbol Huffman. Con lo que cualquier símbolo del conjunto puede ser generado simplemente recorriendo el árbol desde la raíz al nodo hoja. Para ello, cada nodo hoja tiene asignada una probabilidad.
VP8 utiliza una distribución de probabilidad condicional para modelar el contexto que se usa en la codificación de entropía y así poder adaptarlo a sus necesidades. Para ello, mantiene las distribuciones de probabilidad dentro de un marco estable y compatible la actualización de cada fotograma.
De este modo, en un fotograma clave, todas las distribuciones de probabilidad se ponen a la par del fondo por defecto, y luego en cada fotograma posterior se combinan con las actualizaciones individuales para usar el coeficiente de codificación dentro del marco.
Otro aspecto a destacar en este punto, son las características de particionado de las que dispone VP8 para lograr así un uso efectivo de la potencia de cálculo en procesadores multicore. En esencia, VP8 separa inicialmente los datos comprimidos en dos categorías, una usada para los modos de codificación y los vectores de movimiento y otra para los coeficientes del cuantificador.
Además, se permite a estos coeficientes, ser introducido en más de una partición sin necesidad de cambiar las dependencias del macrobloque y se consigue que los contextos de entropía usados sean los mismos que cuando se procesan todos los coeficientes en una misma partición con todos los macrobloques.
4. EVALUACIÓN DE PRESTACIONES: COMPARATIVA VP8 VS H264
Tras las descripciones técnicas de ambas normas, realizaremos a continuación la comparativa mediante una evaluación de prestaciones. Lo que se pretende con ello es dar pie a una extracción de conclusiones sobre el nivel de madurez de cada norma, y sobre todo cuál ofrece mejor rendimiento y en qué escenarios o situaciones.
Para realizar una comparativa completa y justa, deberemos tener en cuenta cuantos más aspectos y prestaciones posibles. Por ello hemos decidido, en base a la información y bibliografía disponible, incluir aspectos que abarcan desde el nivel de integración y madurez del estándar, el apoyo que recibe (quién lo desarrolla, quiénes dan soporte, etc.), el tipo de licencia, etc. hasta otros más técnicos como el nivel de compresión o el comportamiento ante vídeos con más o menos movimiento y más o menos detalles.
El aspecto que consideramos más relevante, y el cual debe ser tenido en cuenta a lo largo de toda la comparativa, es que el nivel de madurez de ambos es muy distinto. Mientras que H264 comenzó a gestarse en 2001, VP8 es mucho más reciente ya que su publicación data de septiembre de 2008, aunque la liberación del códec se produjo a mediados de 2010. Es por ello que aunque en ocasiones se pueda ver que H264 ofrece un mejor rendimiento, todavía cabe la posibilidad de que se introduzcan nuevas mejoras en VP8 que logren mejorar su rendimiento por encima de H264.
Otro aspecto muy importante y que condicionará el uso y avance de uno u otro es el hecho de que H264 es un códec privativo, es decir, es necesario pagar por usarlo, pudiendo llegarse a pagar hasta $6,5 millones anuales por el uso de una licencia [Patentes]. En cambio el códec VP8 está liberado bajo licencia de software libre permisiva [Licencia] con lo cual su uso es gratuito, un aspecto fundamental que sin duda condiciona y mucho el uso de un códec u otro.
En base principalmente a este último aspecto, no han tardado en formarse dos grupos diferentes de apoyo a uno u otro estándar. Este apoyo servirá para decidir en última instancia cuál de los dos estándares será incorporado de forma definitiva en el nuevo lenguaje web HTML5 que todavía está en proceso de maduración y para el cual aún no se ha decidido un códec de video concreto.
Por un lado, VP8, contenido dentro del proyecto WebM [WebM] se perfila como candidato a ser el formato de video estándar en el lenguaje web HTML5, además la Free Software Foundation [http://www.fsf.org ] propuso una iniciativa para que Google sustituya el actual reproductor Adobe Flash Player y el códec H264 en Youtube por VP8. El avance del proyecto WebM y con ello del códec VP8 para su inclusión en HTML5 cuenta con el esfuerzo conjunto de más de 40 editores y fabricantes de software y hardware [Support] entre los que
se incluye el propio Google, Mozilla, Adobe, AMD o NVidia.
En el otro lado de la balanza está H264, que cuenta con fuertes apoyos por parte de empresas como Microsoft, quien ya distribuye su navegador Internet Explorer 9 con soporte para HTML5 con el códec H264, y otras como Apple, además de contar con el apoyo de sus desarrolladores, la Unión Internacional de Telecomunicaciones (ITU) y el Moving Pictures Experts Group (MPEG). También se usa en gran cantidad de aplicaciones de emisión y distribución de contenidos audiovisuales, además de ser el estándar usado para HDTV y en los discos Blu-ray.
VP8 deberá luchar por abrirse hueco en un mercado dominado por el monopolio de H264, el cual se ha convertido poco a poco en el estándar más aceptado, y cuenta con una cuota de mercado incluso superior a Flash y muy por encima de otros minoritarios como Ogg Theora, y con gran cantidad de software que lo implementa.
Entrando ya en la evaluación de prestaciones, los aspectos técnicos que hemos tenido en cuenta para la comparativa han sido:
Comparativa de características:
Comparativas usadas:
- Modos de predicción.
- Transformación y cuantificación.
- Codificador de entropía.
- Filtros in-loop.
- Bit rate
- Medidas de calidad de imagen: PSNR y Semejanza Estructural (SSIM)
- Ratio de compresión
- Complejidad: tiempo de codificación y decodificación
Comparativas usadas:
- Implementation, performance analysis and comparison of H.264 and VP8 Keyur Shah bajo la tutorización del Dr. K. R. Rao - Universidad de Uta (EEUU).
- VP8 vs. H.264 - Jan Ozer (experto en códecs de video desde 1990, autor de 13 libros y colaborador de StreamingMedia.com, Digital Content Producer y EventDV)
- The first in-depth technical analysis of VP8, Jason Garrett-Glaser (Principal desarrollador de x264 y contribuyente al código de FFmpeg)
4.1.1 - Predicción Intraframe
En VP8 encontramos modos de predicción que nos recuerdan a los usados por H.264. En ambos casos encontramos modos de predicción que usan bloques de 4x4, 8x8 y 16x16.
En el caso de la predicción 4x4 y 16x16, VP8 utiliza técnicas similares a H264 para implementarla. VP8 utiliza 10 modos distintos para los de 4x4 mientras que H264 utiliza uno menos, aunque su funcionamiento es muy similar, y 4 modos distintos para los de 16x16. Para estos últimos VP8 utiliza, además de las predicciones Horizontales, Verticales y DC, la predicción TrueMotion, que no está en H264, pero que es muy similar a la predicción de plano que utiliza H264. En cuanto a la predicción de bloques de 8x8 también es prácticamente idéntica.
En este aspecto podemos concluir que los desarrolladores de VP8 no fueron demasiado innovadores en los modos de predicción, y decidieron "reciclar" los que utiliza H264.
4.1.2 - Predicción Interframe
En este punto observamos diferencias más notables. Cuando se realiza la predicción utilizando frames de referencia, H264 utiliza frames de tipo I, P o B y VP8 prescinde de los frames de tipo B y utiliza sólo los de tipo I y P, además de otros dos, los "altref" frames (de referencia alternativa) y los "golden" frames.
El hecho de no usar el frame de tipo B, principalmente por temas de patentes, merma bastante la eficiencia a la hora de aprovechar la redundancia temporal en la predicción intraframe de VP8, aunque al parecer los frames alternos pueden suplir esa ausencia, aunque no de forma tan eficiente.
En cuanto a la distancia de referencia máxima utilizada para los frames de tipo P, VP8 sólo permite una distancia de hasta 3 frames, mientras que en H264 puede referenciar a otro que esté hasta una distancia máxima de 16, además de permitir el uso de predicción ponderada (weighted prediction), y ofrecer la posibilidad de que un frame de tipo B referencia a la vez a un frame pasado y a otro futuro.
En lo referente a la estimación por vector de movimiento, VP8 muestra menos precisión ya que aunque dispone de una amplia configuración de macrobloques (16×16, 16×8, 8×16, 8×8, 4×4), es superado por H264 que dispone además de las configuraciones 8x4, 4x8, aunque al fin y al cabo estas subparticiones son innecesarias en muchas ocasiones, por lo tanto la diferencia no es apreciable. En cuanto a los vectores de movimiento, ambas normas soportan una precisión de un 1, 1/2 y 1/4 de pixel. Por lo tanto podemos concluir que H264 tiene una estructura de referencias mejor y más flexible.
4.2 Transformación y cuantificación
4.2.1 – Transformación
A la hora de realizar la transformación, encontramos un proceso muy similar en ambos, dividiendo cada macrobloque de 16x16 en 16 macrobloques de 4x4, aplicándoles la transformada DCT y posteriormente la transformada Hadamard. Sin embargo se aprecian dos diferencias.
La primera es que VP8 no permite aplicar la transformada a bloques de 8x8, a diferencia de H264 que si lo permite en el modo de alta calidad. La segunda es que los coeficientes usados en la transformada DCT son bastante diferentes. Mientras que H264 opta por una transformación más sencilla, a pesar de perder algo de compresión, VP8 opta por una transformación más precisa y compleja.
Como conclusión podemos decir que aunque VP8 ha mejorado la precisión a la hora de aplicar las transformaciones, esto ha supuesto que el proceso de codificación sea más lento, y además al no permitir aplicar la transformada a bloques de 8x8 perjudica ligeramente la calidad final.
4.2.2 – Cuantificación
En este punto podemos apreciar una gran diferencia que sin duda supone una desventaja para VP8 y es que no implementa la cuantificación adaptativa, cosa que si hace H264, lo cual supone diferencias notables en los resultados finales.
4.3 Codificador de entropía
La codificación de entropía consiste en coger la información de otros procesos como los coeficientes de la transformada DCT, los modos de predicción o los vectores de movimiento y realizar una compresión sin pérdidas que formará parte del archivo de salida final.
En ambos casos utilizan un codificador aritmético, la diferencia más notable de nuevo es la ausencia de un proceso adaptativo para establecer las probabilidades usadas en el codificador por parte de VP8.
4.4 Filtros "in-loop"
Estos filtros se utilizan tras codificar y decodificar un frame, y sirven para mejorar la calidad, por ejemplo reduciendo el efecto bloque. No sólo tiene importancia a efectos visuales, sino también para mejorar la codificación de otros frames que hacen referencia a ese frame.
Tanto VP8 como H264 implementan estos filtros de forma similar, salvo algunas diferencias. La primera es que VP8 implementa dos modos de aplicar los filtros, el modo rápido que es algo más simple que en H264, y el modo normal que es algo más complejo. Otra diferencia a favor de VP8 es que al filtrar entre macrobloques, éste dispone de un mayor rango de filtros, a diferencia de H264.
4.5 Estudio práctico de la comparativa del rendimiento
En esta sección se pretende analizar los resultados obtenidos a la hora de realizar una codificación de una secuencia con ambos codificadores.
En dicho estudio se utilizarán dos programas, ffmpeg: Fast Forwarding Mpeg, versión 0.6.1 para la codificación con H264 y ffvp8, que incluye las librerías de libvpx, para la codificación de VP8. Por último, para calcular la similitud estructural, se utiliza la herramienta MSU Video Quality Measurement Tool 2.7.3.
Añadir que para el estudio se han utilizado dos secuencias: News y Mobile en sus versiones para el tamaño CIF y QCIF de 90 frames las cuales se pueden obtener de la web [http://media.xiph.org/video/derf/], y muestran el comportamiento de ambos estándares para dos tipos de secuencias, en la News tenemos una secuencia con poco nivel de detalle y poco movimiento, mientras que en la Mobile tenemos una secuencia con algo de movimiento y con un alto nivel de detalle y variedad de colores.
4.5.1 - Secuencia News
A continuación se muestran los resultados de la codificación de la secuencia News en el formato CIF con el codificador H264 (Tabla 1) y con VP8 (Tabla 2) que se han obtenido con las herramientas citadas anteriormente:
Factor de
Cuantificación
|
Tiempo de
codificación (sec)
|
Bit Rate
(kbits/sec)
|
PSNR (dB)
|
SSIM
|
Ratio de
compresión
| |
2
|
0.140
|
1219.4
|
44.17
|
0.9838
|
83.12
| |
4
|
0.109
|
607.5
|
40.42
|
0.9727
|
166.90
| |
8
|
0.062
|
303.6
|
36.28
|
0.9505
|
332.48
| |
12
|
0.109
|
202.8
|
33.87
|
0.9321
|
495.00
| |
16
|
0.109
|
153.9
|
32.21
|
0.9135
|
655.10
| |
20
|
0.109
|
123.8
|
30.94
|
0.8961
|
810.00
| |
24
|
0.125
|
105.4
|
29.93
|
0.8800
|
947.90
| |
28
|
0.140
|
92.5
|
29.09
|
0.8676
|
1086.10
| |
32
|
0.156
|
84.6
|
28.53
|
0.8562
|
1172.40
| |
48
|
0.094
|
83.8
|
28.42
|
0.85422
|
1204.10
| |
64
|
0.109
|
83.6
|
28.35
|
0.8535
|
1204.10
| |
Tabla 1- H264 news_cif.yuv (90 frames)
Factor de
Cuantificación
|
Tiempo de
codificación (sec)
|
Bit Rate
(kbits/sec)
|
PSNR (dB)
|
SSIM
|
Ratio de
compresión
| |
2
|
2.075
|
2205.9
|
44.62
|
0.9814
|
45.93
| |
4
|
1.950
|
1619.0
|
43.21
|
0.9708
|
50.86
| |
8
|
1.810
|
965.7
|
40.26
|
0.9681
|
104.82
| |
12
|
1.778
|
705.0
|
39.12
|
0.9578
|
143.71
| |
16
|
1.685
|
568.7
|
37.93
|
0.9346
|
178.20
| |
20
|
1.669
|
464.1
|
36.07
|
0.9244
|
218.38
| |
24
|
1.576
|
415.6
|
35.51
|
0.9173
|
243.44
| |
28
|
1.576
|
348.0
|
33.98
|
0.9037
|
291.18
| |
32
|
1.498
|
290.3
|
32.87
|
0.8972
|
348.05
| |
48
|
1.451
|
131.0
|
28.54
|
0.8627
|
768.10
| |
64
|
1.232
|
62.3
|
24.31
|
0.8296
|
1591.07
| |
Tabla 2- VP8 news_cif.yuv (90 frames)
Una vez recogidos los datos en las tablas de ambos codificadores, procedemos a realizar las gráficas habituales para poder hacer una comparativa en la que se muestren cuál de los dos codificadores es mejor. Las siguientes imágenes muestran la comparativa

Figura 14 - Bit rate/Ratio de compresión - [Keyur11]
En esta gráfica se observa que H.264 es capaz de utilizar un menor grueso al comprimir que VP8 cuando el caudal está igual de lleno. Aunque como vamos a ver en las siguientes gráficas, es en la que más igualados están los estándares.

Figura 15 - Bit rate/PSNR - [Keyur11]
En esta gráfica se observa cómo es más eficiente el codificador H264 que VP8, ya que en todo momento la línea roja (H264) se encuentra por encima de la verde (VP8), esto significa que usando el mismo caudal de bits, se obtiene mayor calidad (PSNR) con el codificador H264.

Figura 16 - Bit rate/SSIM - [Keyur11]
En la figura 16 también vemos que H264 al utilizar el mismo caudal de bits guarda más semejanzas con respecto a la imagen original que al codificar con Vp8.
A continuación se muestran los resultados de la codificación de la secuencia News en el formato QCIF con el codificador H264 (Tabla 3) y con VP8 (Tabla 4) que se han obtenido con las herramientas citadas anteriormente:
Factor de
Cuantificación
|
Tiempo de codificación (sec)
|
Bit Rate
(kbits/sec)
|
PSNR (dB)
|
SSIM
|
Ratio de compresión
| |
2
|
0.047
|
413.6
|
43.57
|
0.9886
|
61.2
| |
4
|
0.047
|
217.8
|
39.07
|
0.9757
|
116.0
| |
8
|
0.047
|
110.3
|
34.41
|
0.9462
|
227.3
| |
12
|
0.031
|
72.3
|
31.84
|
0.9161
|
348.1
| |
16
|
0.047
|
54.7
|
30.15
|
0.8888
|
445.5
| |
20
|
0.016
|
44.0
|
28.87
|
0.8615
|
556.9
| |
24
|
0.047
|
37.3
|
27.84
|
0.8357
|
655.2
| |
28
|
0.047
|
32.5
|
26.99
|
0.8171
|
742.5
| |
32
|
0.047
|
30.6
|
26.41
|
0.8026
|
795.6
| |
48
|
0.047
|
29.6
|
26.35
|
0.8044
|
795.6
| |
64
|
0.047
|
29.6
|
26.30
|
0.8022
|
856.8
| |
Tabla 3- H264 news_qcif.yuv (90 frames)
Factor de
Cuantificación
|
Tiempo de
codificación (sec)
|
Bit Rate
(kbits/sec)
|
PSNR (dB)
|
SSIM
|
Ratio de
compresión
| |
2
|
0.608
|
611.1
|
42.93
|
0.9862
|
41.40
| |
4
|
0.577
|
601.4
|
42.27
|
0.9817
|
42.03
| |
8
|
0.546
|
327.5
|
39.36
|
0.9624
|
77.35
| |
12
|
0.530
|
249.8
|
37.82
|
0.9526
|
101.25
| |
16
|
0.499
|
207.9
|
36.38
|
0.9476
|
121.07
| |
20
|
0.477
|
173.8
|
34.54
|
0.9373
|
144.65
| |
24
|
0.461
|
156.4
|
33.48
|
0.9243
|
161.42
| |
28
|
0.450
|
134.1
|
32.89
|
0.9121
|
188.78
| |
32
|
0.450
|
113.2
|
31.94
|
0.9041
|
222.76
| |
48
|
0.450
|
51.7
|
27.83
|
0.8447
|
484.26
| |
64
|
0.410
|
25.2
|
24.69
|
0.7877
|
928.17
| |
Tabla 4- VP8 news_qcif.yuv (90 frames)
Una vez recogidos los datos en las tablas de ambos codificadores, procedemos a realizar las gráficas habituales para poder hacer una comparativa en la que se muestren cuál de los dos codificadores es mejor. Las siguientes imágenes muestran la comparativa:

Figura 17 - Bit rate/Ratio de compresión - [Keyur11]

Figura 18 - Bit rate/PSNR - [Keyur11]

Figura 19 - Bit rate/SSIM - [Keyur11]
El análisis de las gráficas de la secuencia QCIF es similar al de las gráficas de CIF ya que no se aprecian diferencias notables que nos den pie a otras conclusiones.
4.5.2 - Secuencia Mobile
A continuación se muestran los resultados de la codificación de la secuencia Mobile en el formato CIF con el codificador H264 (Tabla 5) y con VP8 (Tabla 6) que se han obtenido con las herramientas citadas anteriormente:
Factor de
Cuantificación
|
Tiempo de
codificación (sec)
|
Bit Rate
(kbits/sec)
|
PSNR (dB)
|
SSIM
|
Ratio de
compresión
| |
2
|
0.234
|
8503.3
|
41.37
|
0.9911
|
11.92
| |
4
|
0.203
|
4513.8
|
36.23
|
0.9774
|
22.87
| |
8
|
0.203
|
2121.9
|
31.07
|
0.9431
|
47.75
| |
12
|
0.218
|
1273.1
|
28.30
|
0.9038
|
79.55
| |
16
|
0.156
|
864.3
|
26.53
|
0.8655
|
117.24
| |
20
|
0.140
|
622.5
|
25.19
|
0.8263
|
162.60
| |
24
|
0.125
|
476.4
|
24.19
|
0.7871
|
212.10
| |
28
|
0.125
|
378.9
|
23.40
|
0.7545
|
266.80
| |
32
|
0.125
|
324.7
|
22.88
|
0.7303
|
311.50
| |
48
|
0.094
|
326.2
|
22.84
|
0.7316
|
309.40
| |
64
|
0.078
|
329.3
|
22.80
|
0.7311
|
307.20
|
T
Tabla 5- H264 mobile_cif.yuv (90 frames)
Tabla 5- H264 mobile_cif.yuv (90 frames)
Factor de
Cuantificación
|
Tiempo de
codificación (sec)
|
Bit Rate
(kbits/sec)
|
PSNR (dB)
|
SSIM
|
Ratio de
compresión
| |
2
|
4.384
|
8180.5
|
39.64
|
0.9773
|
12.39
| |
4
|
4.246
|
7558.4
|
38.93
|
0.9692
|
13.41
| |
8
|
4.009
|
4860.4
|
34.06
|
0.9421
|
20.86
| |
12
|
3.916
|
3807.6
|
33.01
|
0.9298
|
26.63
| |
16
|
3.775
|
3166.5
|
31.96
|
0.9146
|
32.00
| |
20
|
3.557
|
2622.3
|
30.63
|
0.8919
|
38.64
| |
24
|
3.510
|
2371.3
|
29.41
|
0.8864
|
42.71
| |
28
|
3.385
|
2001.6
|
28.47
|
0.8712
|
50.63
| |
32
|
3.370
|
1650.1
|
27.61
|
0.8586
|
61.36
| |
48
|
3.058
|
584.4
|
24.15
|
0.7844
|
173.35
| |
64
|
2.605
|
197.7
|
21.58
|
0.6847
|
512.00
| |
Tabla 6- VP8 mobile_cif.yuv (90 frames)
Una vez recogidos los datos en las tablas de ambos codificadores, procedemos a realizar las gráficas habituales para poder hacer una comparativa en la que se muestren cuál de los dos codificadores es mejor. Las siguientes imágenes muestran la comparativa

Figura 20 - Bit rate/Ratio de compresión - [Keyur11]
En esta gráfica se puede observar un comportamiento muy parecido al de la secuencia News, en la que vemos como para un determinado flujo en el caudal de bits, el ratio de compresión es muy parecido tanto en H264 como en VP8. La pega aparece para flujos bajos en el caudal de bits, en la que vemos que el ratio de compresión es mucho menos en H264 que en VP8.
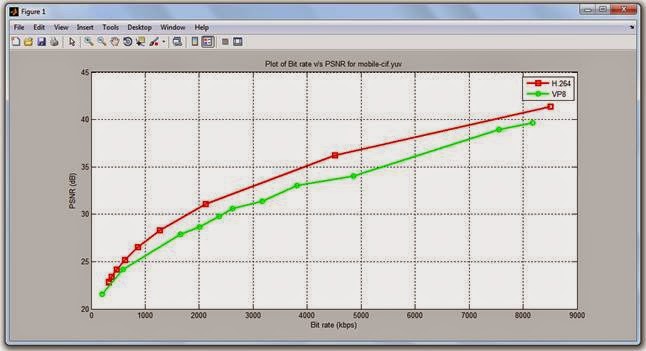
Figura 21 - Bit rate/PSNR - [Keyur11]
En esta gráfica, observamos que, como la secuencia mobile es una secuencia con muchísimos más detalles que la news existe menos diferencia en la parábola que se forma, se observaba anteriormente que para conseguir un PSNR muy elevado con H264 se necesitaba un caudal de 1300 en H264 y mil más para obtener un PSNR parecido con VP8, sin embargo aquí las distancias se reducen más, aunque H264 sigue siendo superior a VP8.

Figura 22 - Bit rate/SSIM - [Keyur11]
En la gráfica anterior vemos que para caudales bajos, las semejanzas con respecto a las imágenes reales, son parecidas entre ambos codificadores….pero con caudales medios vemos como VP8 pierde mucha más semejanza, aunque con caudales de bits elevados, se va recuperando el equilibro entre ambos codificadores, aunque el claro ganador es el H264.
A continuación se muestran los resultados de la codificación de la secuencia Mobile en el formato QCIF con el codificador H264 (Tabla 7) y con VP8 (Tabla 8) que se han obtenido con las herramientas citadas anteriormente:
Factor de
Cuantificación
|
Tiempo de
codificación (sec)
|
Bit Rate
(kbits/sec)
|
PSNR (dB)
|
SSIM
|
Ratio de
compresión
| |
2
|
0.078
|
2390.9
|
40.8
|
0.9933
|
10.60
| |
4
|
0.094
|
1255.0
|
35.28
|
0.9790
|
20.18
| |
8
|
0.047
|
566.1
|
29.94
|
0.9369
|
44.73
| |
12
|
0.062
|
323.0
|
27.21
|
0.8841
|
78.44
| |
16
|
0.031
|
208.5
|
25.52
|
0.8370
|
121.07
| |
20
|
0.047
|
145.0
|
24.29
|
0.7883
|
174.03
| |
24
|
0.047
|
108.2
|
23.37
|
0.7383
|
232.04
| |
28
|
0.062
|
84.5
|
22.65
|
0.6995
|
293.10
| |
32
|
0.016
|
71.8
|
22.19
|
0.6729
|
348.10
| |
48
|
0.047
|
72.2
|
22.15
|
0.6714
|
348.10
| |
64
|
0.047
|
73.0
|
22.11
|
0.6717
|
337.50
|
Tabla 7- H264 mobile_qcif.yuv (90 frames)
Factor de
Cuantificación
|
Tiempo de codificación (sec)
|
Bit Rate
(kbits/sec)
|
PSNR (dB)
|
SSIM
|
Ratio de compresión
| |
2
|
1.092
|
2149.3
|
38.81
|
0.9862
|
11.79
| |
4
|
1.039
|
1962.5
|
37.74
|
0.9732
|
12.91
| |
8
|
1.016
|
1285.2
|
33.12
|
0.9548
|
19.71
| |
12
|
0.996
|
1001.9
|
31.46
|
0.9321
|
25.26
| |
16
|
0.996
|
832.3
|
29.72
|
0.9233
|
30.43
| |
20
|
0.952
|
691.0
|
28.07
|
0.8965
|
36.64
| |
24
|
0.952
|
623.4
|
27.35
|
0.8831
|
40.65
| |
28
|
0.842
|
524.9
|
26.48
|
0.8724
|
48.22
| |
32
|
0.820
|
431.0
|
25.84
|
0.8612
|
58.62
| |
48
|
0.780
|
154.8
|
22.61
|
0.7548
|
161.42
| |
64
|
0.686
|
53.6
|
20.36
|
0.6483
|
464.08
| |
Tabla 8- VP8 mobile_qcif.yuv (90 frames)
Una vez recogidos los datos en las tablas de ambos codificadores, procedemos a realizar las gráficas habituales para poder hacer una comparativa en la que se muestren cuál de los dos codificadores es mejor. Las siguientes imágenes muestran la comparativa.

Figura 23 - Bit rate/Ratio de compresión - [Keyur11]

Figura 24 - Bit rate/PSNR - [Keyur11]

Figura 25 - Bit rate/SSIM - [Keyur11]
Para esta secuencia, de nuevo el análisis de las gráficas QCIF es similar al de las gráficas de CIF ya que tampoco se aprecian diferencias notables.
Por último observamos una comparativa del tiempo empleado para la codificación de cada una de las secuencias por parte de VP8 y H.264

Figura 26 - Tiempos de codificación - [Keyur11]
Se aprecia que VP8 emplea mucho más tiempo en el proceso, sobre todo si el nivel de detalle es muy alto y el tamaño del frame no es reducido, como ocurre con la secuencia Mobile en su versión CIF.
4.6 Análisis de frames
En esta sección, se pretende analizar visualmente algunos ejemplos de codificación de secuencias utilizando H264 y VP8. Este análisis se ha obtenido de un estudió que realizó Jan Ozer [Ozer10].
En primer lugar vamos a tomar una secuencia en la que no existe mucho movimiento, similar a la secuencia News del apartado anterior, en la que se puede comprobar que tanto en VP8 (a la derecha) como en H264 (a la izquierda), las diferencias son prácticamente inexistentes:

Figura 27 - Codificación de secuencia con poco movimiento - [Ozer10]
En la siguiente secuencia, que tiene un movimiento lento, pero sin embargo el fondo tiene muchos detalles para codificar, también se observa que VP8 es capaz de mantener muy bien esos detalles con respecto a la codificación con H264:

Figura 28 - Codificación de secuencia con movimiento lento - [Ozer10]
Sin embargo, en los dos ejemplos que vamos a ver a continuación, que son secuencias con contienen un movimiento más rápido, vamos a observar como H264 es superior a VP8.
En la siguiente secuencia, vemos como tanto en la masa como en la camisa de rayas, se aprecia con mucha diferencia el efecto bloque que genera VP8 mientras H264 funciona mucho mejor. En general toda la imagen se aprecia más nítida con H264:

Figura 29 - Codificación de una imagen con movimientos rápidos - [Ozer10]
Y por último, en la siguiente secuencia con mucho movimiento y muy rápido observamos que H264 también es algo superior ya que guarda mejor los detalles del fondo (observar zonas señaladas):

Figura 30 - Codificación de una imagen con mucha cantidad de movimientos rápidos - [Ozer10]
5. CONCLUSIONES
La conclusión más importante que obtenemos es que a pesar de que VP8 todavía no supera a H264 en muchos de los aspectos, se augura un futuro prometedor para este estándar.
Se ha buscado en VP8 una codificación más sencilla pero a la vez equiparable a H264, pero sin duda la falta de los frames de tipo B supone una desventaja muy considerable en cuanto a ineficiencia, ello sumado a la menor precisión en los procesos de predicción hace que VP8 aún tenga mucho camino por recorrer, y posiblemente en un futuro no muy lejano se consigan resultados mejores que con H.264.
Otro factor a mejorar sin duda es la velocidad de codificación, algo en lo que ya se trabaja y que se ha conseguido reducir en pequeños porcentajes.
Además VP8 cuenta con otro problema, y es el de las patentes, podría decirse que VP8 es prácticamente H264 con perfil baseline y con un codificador de entropía mejorado, por lo tanto hay varias cuestiones relativas a las patentes de H264 que Google deberá justificar, y todo parece indicar que será una tarea difícil.
Con todo ello, Google sigue trabajando en mejorar día a día este prometedor estándar, aunque será una tarea difícil ya que ya hay muchas compañías de software que ofrecen soporte para VP8, y cuanto más software ofrece soporte para un formato de fichero, más difícil es renovarlo.
A pesar de todo, no siempre el mejor gana en las batalla. Como se ha visto en situaciones similares como el caso del VCR y la lucha entre los formatos Betamax y VHS la cual ganó este último a pesar de que el Betamax siempre fue mejor en cuanto a calidad de imagen, en este tipo de situaciones gana quien tenga más apoyo (no siempre el mejor). Si Google compró On2 (y con ello VP8) fue evidentemente con el objetivo de usarlo en Youtube, ergo, desplazará no solo al H264 sino a cualquier otro por el simple hecho de ser el más usado. Otra cuestión importante es si VP8 permanecerá liberado para siempre. Si es así y además su uso comienza a extenderse como ya lo está haciendo, el H264 está destinado a desaparecer.








0 comentarios:
Publicar un comentario